Umjetna ili prividna inteligencija?
Često samo ime tehnologije diktira zaključke o njoj. Velik broj alata zasnovan na strojnom učenju nazivamo UI-jem, povezujući ih time s ciljem da jednog dana stvorimo umjetni um. No takvo imenovanje većini korisnika predlaže krivu sliku o tome što je sadašnja umjetna inteligencija i kakve su njezine mogućnosti

Proteklih godina radeći s kolegama i kolegicama zgrozila me jedna nova navika. Ne, nije to bila zadivljenost ispraznim TikTok uracima, ali to je tema za jedan drugi tekst. Bila je to njihova sklonost da kad nešto ne znaju, više ne upisuju tražene termine i pitanja u tražilice, već u ChatGPT.
ChatGPT jest produkt strojnog učenja, ali nije baza podataka niti je on sposoban razmišljati o odgovorima, ali ljude zavaravaju dvije stvari kod njega. Jedno je da nastoji svoje odgovore sročiti u konverzacijskom tonu, a druga je da ga nazivamo umjetnom inteligencijom.
Ako pitate bilo kojeg psihologa što je inteligencija, počet će čupati kosu ili odgovoriti mudrolijom da je inteligencija ono što mjere testovi inteligencije. Inteligenciju je teško definirati, ali obično sve definicije uključuju sposobnost rješavanja problema i razmišljanja.
San i cilj gotovo svih znanstvenika je jednog dana napraviti pravu umjetnu inteligenciju, nešto što u trenutačnoj terminologiji nazivamo AGI (Artificial General Intelligence). Uz njega je u filozofiji vezana hipoteza o jakom UI-ju odnosno teza da ako napravimo stroj koji se može ponašati poput ljudskog uma, onda će i stroj biti svjestan. AGI ne postoji, ali divovi poput OpenAI-ja, pa čak i Meta, žele ga postići, i to čim prije. Prema trenutačnoj terminologiji, imamo samo slab UI, odnosno uski UI, koji je sposoban obavljati samo specifične zadatke, bilo to prepoznavanje pjesama, bilo autocorrecta.
Da, ako malo razmislimo, prema toj definiciji, UI koristimo već vrlo dugo. Spomenuti autocorrect oblik je algoritma koji obavlja jednostavan zadatak, a patentirao ga je Dean Hachamovitch 1998. godine, radeći na Wordu. Jedan drugi alat koji je također oblik UI-ja, flash fill, uveden je s Excelom 2013. godine. Prediktivni tekst na pametnim uređajima, vjerovali ili ne, vuče korijene još iz pedesetih godina 20. stoljeća, kada su slične algoritme morali izmisliti kineski znanstvenici i lingvisti, kako bi mogli konstruirati tipkovnice za mandarinski jezik, koji ima pet do šest tisuća logograma. Na prvim mobitelima pojavio se 1995. godine.
No, niti jedan od tih alata ne razmišlja, već bazira svoje rezultate na algoritmima, pravilima utemeljenim na statistici. Bilo kakav nepredviđeni unos zbunit će sustav, dok i mala djeca (a prema nekim antropološkim istraživanjima i primati) mogu pogađati značenja riječi ili stvarati sasvim nove riječi.
Nazivajući sve produkte bazirane na strojnom učenju, ili kako bi cinici rekli podatkovnoj znanosti (ili još veći cinici na statistici i linearnoj algebri) umjetnom inteligencijom, dopustili smo pretpostavku da o svim alatima strojnog učenja razmišljamo kao o alatima koji mogu razmišljati. I tu je problem.
Što leži u imenu
I dan-danas postoji velik otpor prema umjetnoj oplodnji. Radi se o nazivu koji nije točan, već bi trebao glasiti (medicinski) potpomognuta oplodnja, jer u svim njenim oblicima nema ničeg umjetnog, već samo potpomognutog, a proces oplodnje jajne stanice i njezina razvitka u fetus potpuno je prirodan i trudnoće se ne razlikuju od onih započetih spolnim odnosom . No, sâm naziv implicira da umjetna oplodnja daje "umjetnu" djecu, odnosno djecu i ljude koji nisu poput druge.
Zahvaljujući tome, danas konzervativni krugovi kritiziraju postupak kao nemoralan, bezbožan, neprirodan i drugim pogrdnim pridjevima, a nažalost, većina ljudi i dalje koristi termin umjetna umjesto potpomognuta oplodnja.
To je primjer kako pogrešno nazivlje može stvoriti temelje za pogrešno shvaćanje neke tehnologije. Problem korištenja riječi inteligencija za strojno učenje je u tome što ljudi tim tehnologijama pridaju sposobnosti koje one nemaju. Ovo je pogotovo postao problem posljednjih godina sa širokim usvajanjem alata zasnovanih na LLM-ovima i GPT-ima. Zahvaljujući tome što nakon godina istraživanja, ulaganja novca i vremena, pukog procesiranja i anotiranja ogromne količine teksta imamo tekstualno sučelje koje može davati konverzacijske odgovore (koji s lakoćom mogu proći Turingov test), većina korisnika počela je miješati davanje odgovora s razmišljanjem o odgovorima.
Dominantni oblici UI-ja u današnjem svijetu su generativni, što znači da stvaraju rezultate, a proces kojim ih stvaraju je statistika, ne razmišljanje. Udaljenost između (značenja) riječi, algoritmi za eliminaciju disruptivnih pojmova, ili koji prepravljaju specifične kulturalne probleme (znate li da je u Danskoj naziv za radno mjesto prodavača "časnik za zatvaranje"?) uvježbani na velikoj knjižnici podataka prikupljenih s Interneta, daje naizgled vrlo smislene odgovore.
Čudo generativnih alata nije u tome da misle i analiziraju, već da mogu dati toliko dobre rezultate samo industrijskim skaliranjem statističkih pravila. No, ljudi misle da umjetna inteligencija misli kao i oni.

Fake it until you make it
Kada za nekoga kažemo da je inteligentan, onda pretpostavljamo da mnogo razmišlja. U istraživanjima pet temeljnih osobinama ličnosti (koja su nastojala odozdo provjeriti odgovaraju li zaista teoretski pretpostavljenim) među različitim kulturama, inteligencija se pojavila kao jedna od varijacija imena za dimenziju ličnosti, koju inače zovemo otvorenost (uz nazive poput moralnosti i intelektualnosti). Ljudi načelno misle, ne samo da je inteligencija sposobnost koju svi imamo u manjoj ili većoj mjeri, već je i povezuju s osobinom ličnosti.
Nadalje, koliko god se stoljećima govorilo da ljudi ne vjeruju inteligentnim osobama, istraživanja pokazuju da nije stvar u razlikama u inteligencije, već u mentalnom sklopu. Ljudi ne vjeruju ljudima koji mogu pokazati da su oni u krivu, a pritom je nevažno je li ta osoba inteligentna ili ne (primjerice, bitniji je autoritet koji može doći i od imovine ili društvenih veza). No te dvije stvari se brkaju u popularnom shvaćanju, i postoji netočno uvjerenje da javnost ne vjeruje inteligentnim osobama.
Vratimo se na pojam umjetna inteligencija. Dok tražilice nastoje povezati korisnike s točnim odgovorima na Internetu, GPT nastoji ih predvidjeti (možda je bolje reći pogoditi). No, upravo riječ umjetna u njenom nazivu predlaže da su inteligencija i razmišljanje postignuti. Puno bolji i točniji naziv bio bi da je usvojen naziv prividne inteligencije, jer algoritmi postižu privid, a ne stvarnu umjetnu inteligenciju. A upravo je privid ključ.
Uzmimo za primjer prividnu stvarnost. Za nju nikad nije usvojen naziv umjetna stvarnost, jer je svima jasno da riječ virtualnost znači privid (razmatranje činjenice da se umjetna stvarnost katkad koristi kao sinonim za augmented reality samo bi nas vodilo napuštanju teme). Uostalom, usprkos bacanju milijardi dolara na razvoj realistično izgledajuće virtualne stvarnosti, niti tvrtke poput Mete nisu postigle vidljive korake prema dugo spekuliranoj fotorealističnosti virtualnih svjetova. Ako se to i dogodi jednog dana, nećemo ih zvati umjetnim, već prividnim svjetovima.
Ipak nije sve u imenu
Iako je veliki čimbenik to što ChatGPT i slične programe nazivamo UI-jem, potrebno je naglasiti da oni običnim ljudima uistinu izgledaju poput stvarne inteligencije. Primjerice, prilikom traženja informacija na Googleu, potrebno je utipkati točnu frazu, klikati na poveznice, čitati ih i vraćati se na početne rezultate, dok se ne nađu zadovoljavajući rezultati.
GPT nudi iluziju neprekidnog razgovora. Svaki odgovor generira se kao cjelina na zahtjev, a moguće je zatražiti da se odgovor proširi, promijeni ili poveže s nekim ranijim ili novim upitom, baš kao što bi to mogla i prava osoba. Korištenjem Googlea i drugih tražilica, koje ne izmišljaju informacije, ta iluzija nije moguća. One su shvatile da je ta iluzija mamac koji je privukao stotine milijuna korisnika na korištenje GPT-ja.
Kod GPT-ja korisnici imaju osjećaj kao da neprekidno razgovaraju s vrlo inteligentnom i svestranom osobom, dok kod tražilica imaju osjećaj kao da bezuspješno pretražuju knjižnični katalog i čitaju isječke knjiga dok ne pronađu odgovor. Jasno je zašto tražilice ne smatramo umjetnom inteligencijom, dok generativne programe smatramo UI-jem, jer njihov dizajn uistinu daje privid razmišljanja.
Više novijih istraživanja pokazalo je da prosječni korisnici uistinu preferiraju ChatGPT u odnosu na Google zbog više razloga. ChatGPT lijepo im oblikuje odgovore, dok su Googleovi odgovori u obliku poveznica koje je potrebno čitati jednu po jednu. Korisnici skloni ChatGPT-ju ulagali su manje vremena u istraživanje nego oni koji su više koristili Google, pa GPT-jevi zapravo igraju, ne samo na našu sklonost prirodno zvučećim odgovorima, već na našu kognitivnu lijenost.
Osim toga, jednim od ključnih čimbenika pokazalo se to što se LLM-ovi trude ispričati za pogreške, nude prijedloge i zahvaljuju za kvalitetna pitanja. Baš kao što bi napravio zanimljiv sugovornik. Nije niti čudno zašto se Google i druge tehnološke kompanije utrkuju kako napraviti svoje verzije LLM UI-ja.
Izmisli nešto ako ne znaš
Svaka nova tehnologija obično se prvo koristi za dvije stvari – rješavanje matematike i pornografiju. Kako je pornografija namjerno isključena iz brenda ChatGPT-ja, mnogi učenici diljem svijeta pokušali su iskoristiti umjetnu inteligenciju za rješavanje njihove domaće zadaće umjesto njih.
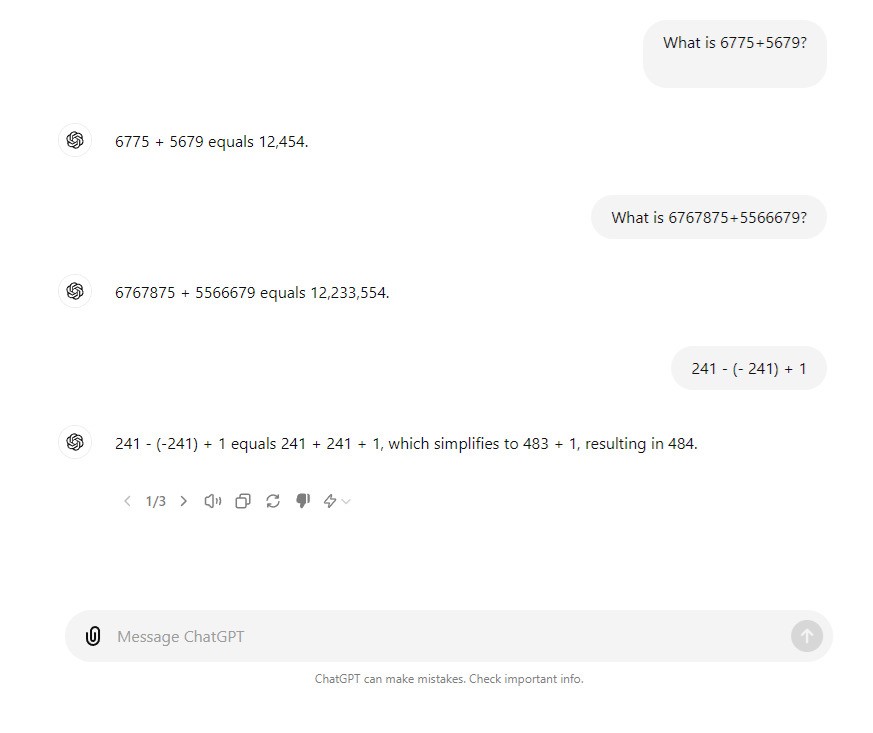
U dosta slučajeva ChatGPT je to mogao, ali samo zato što je u svojoj knjižnici već naišao na sličan zadatak i pripadajuće rješenje. I sada ChatGPT-3.5 može zbuniti jednostavan matematički problem koji bi osnovnoškolac iz nižih razreda mogao riješiti bez problema.
Primjerice, ako ga priupitamo da zbroji 7,5+8+6,6+5+7,7+6,7+6,5, ChatGPT-3.5 dao je netočan rezultat od 48,5 (a ne 48). Situacija se poboljša ako ga zatražimo da ponovi jednadžbu ili prijeđemo na noviji model GPT-4 ili GPT-4o. Situacija je bila puno lošija prije samo tri mjeseca. Kao što je vidljivo na slici koja prati tekst (primjetljiva je razlika u dizajnu sučelja), na pitanja kojima su točni odgovori 48.3 i 14 ChatGPT-3.5 dao je odgovore 48.8 i 19.
Kakva je to umjetna inteligencija koja nema funkcionalnosti osnovnog kalkulatora? Zato je u posljednje verzije ChatGPT-ja ugrađen kalkulator koji razbija i objašnjava korake, ali kao što gore navedeni primjer pokazuje, i dalje ga nije teško zbuniti.
No, aritmetički problemi nisu najveći problem sadašnjeg UI-ja – više o tome u okviru sa strane.
Odsad je ChatGPT moj najbolji prijatelj
Vrativši se na uvod, bio sam zgrožen kada sam shvatio koliko je mojih kolega koristilo ChatGPT za pronalaženje odgovora, čak i kada se radilo o pitanjima za koja su tražilice logički bolje, poput vodiča za sučelja (koji često uključuju screenshotove ili videovodiče). ChatGPT jednostavno im se činio dovoljno pametnim da i na to odgovori, premda bi upućeni trebali znali da bi mogao i halucinirati odgovore koji otprilike točno zvuče.
Svi generativni alati i dalje osciliraju u kvaliteti svojih uradaka i zahtijevaju stalnu prilagodbu algoritama i zakrpe. Istodobno, gotovo svaki mjesec pojavljuje se novi proizvod ili značajno poboljšanje postojećih. U ne tako dalekoj budućnosti sadržaji generirani UI-jem bit će većinski točni, ili barem toliko da neupućeni ne mogu odmah posumnjati u rezultate. Hoće li taj postotak biti 60, 70 ili 80% nije važno, ali je bitan ovaj ostatak.
U jednom trenutku UI bit će dovoljno točan da nećemo moći znati koliko detalja iz njih je točno ili netočno. Ljudi su i sada katastrofalno loši u razlikovanju sponzoriranih tekstova od standardnih novinarskih tekstova (tek desetina to može napraviti, čak i uz jasne obavijesti da se radi o sponzoriranom tekstu) i nisu sposobni razlikovati prikrivene reklame od informativnog sadržaja. Kako će onda prepoznavati halucinacije, ako nisu već upoznati s odgovorom?
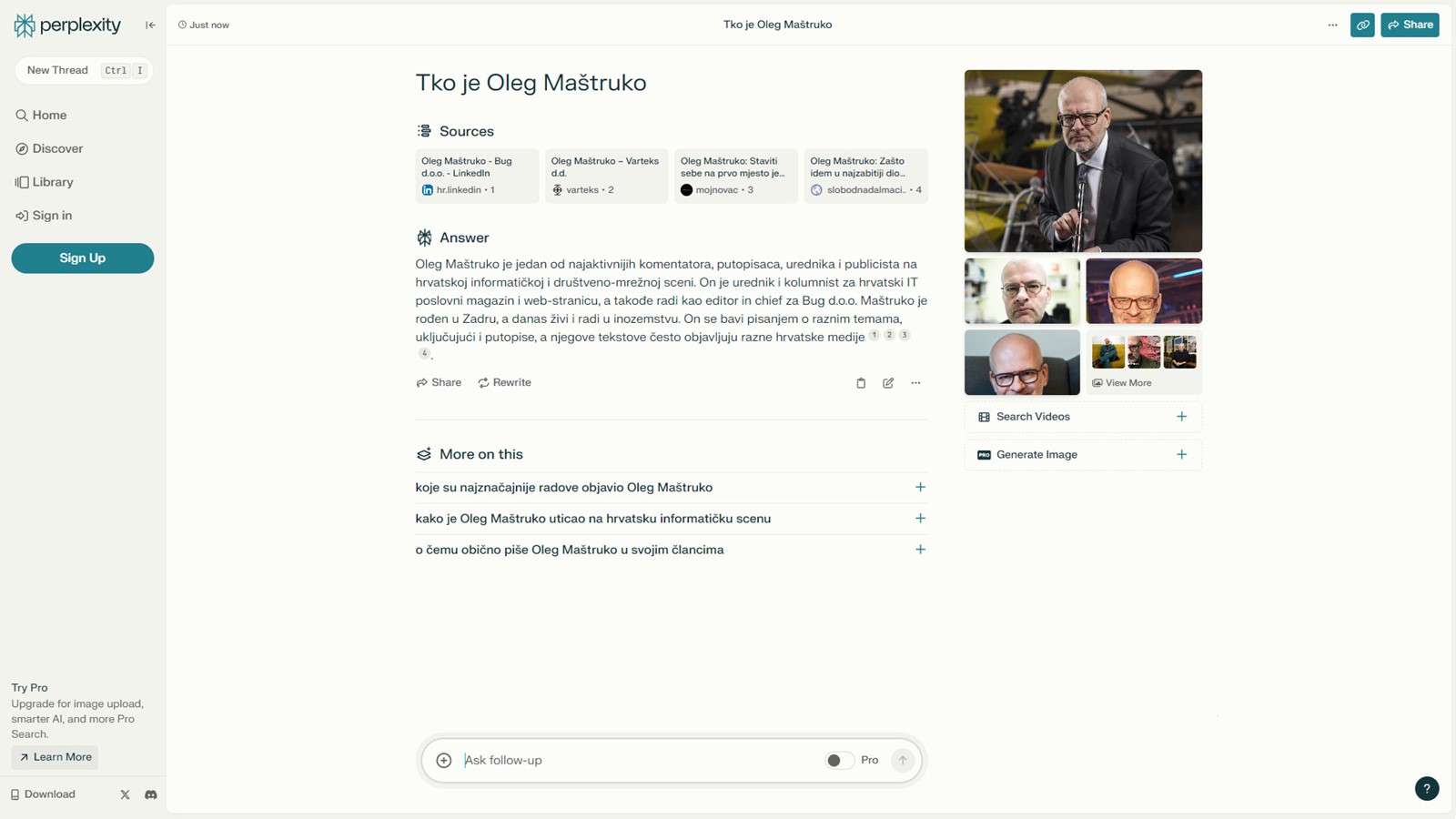
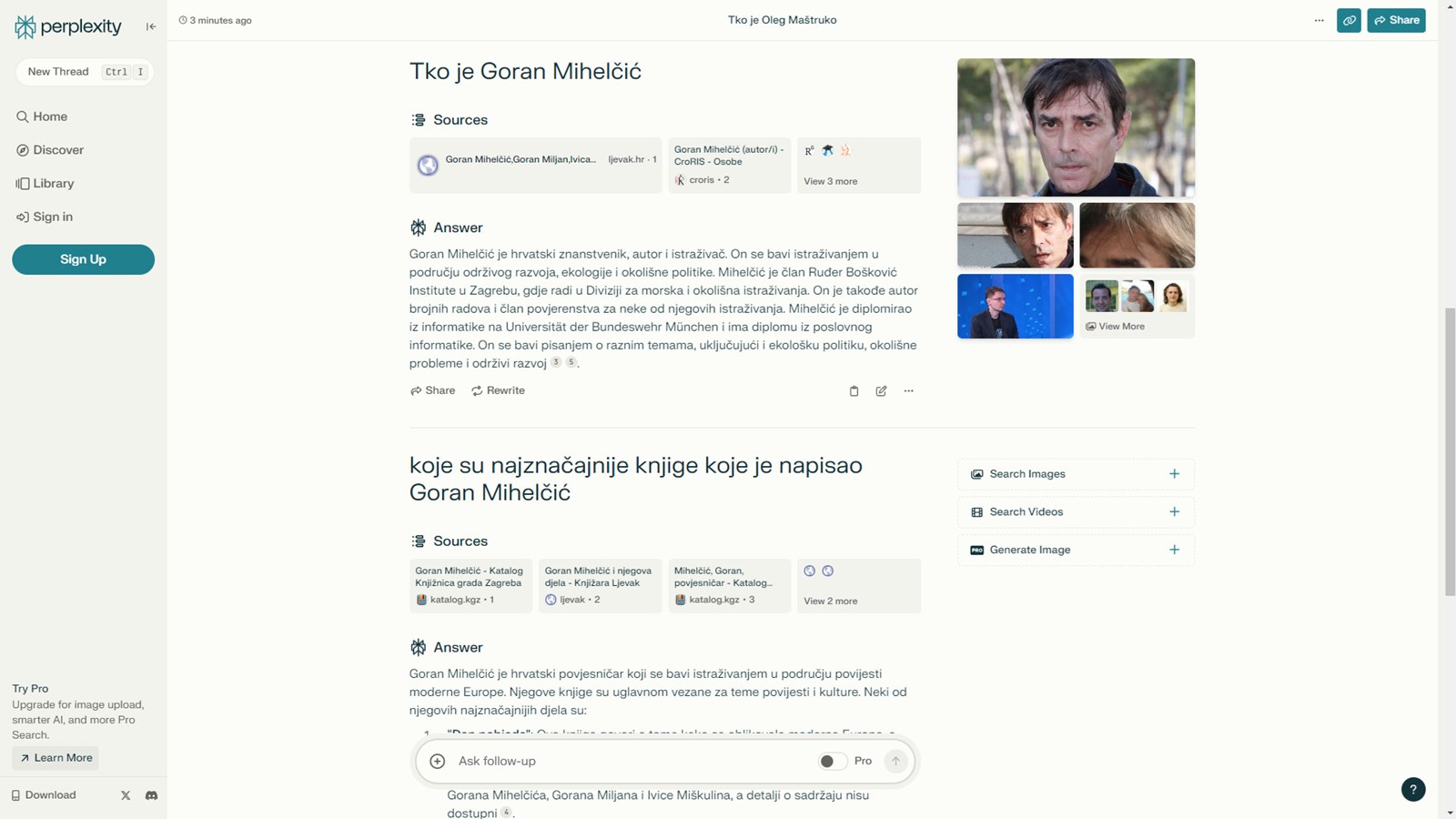
Svjesni tog problema, postoje i pokušaji UI-jem potpomognutih pretraživača, poput Perplexityja (koji podupire i Jeff Bezos). Oni su zasad i najbolje i najgore od oba svijeta. U primjerima na slici, Perplexity je dao prilično točan opis urednika ovog časopisa, ali potpuno se zbunio kod autora ovog teksta, spojivši podatke o njemu iz tri-četiri imenjaka. S obzirom na to da ne može razmišljati, ne može niti uvidjeti da se radi o nekoliko različitih osoba, nešto što bi prosječna osoba zaključila odmah, barem na temelju fotografija.

Budućnost prividne informiranosti
Učitelji i profesori informatike primjećuju iz godine u godinu da njihovi učenici i studenti postaju manje pismeni od njih samih, umjesto tehnološki spretniji od njih. Probleme im predstavljaju kopiranje datoteke iz jedne mape u drugu (što se može učiniti jednostavnim povlačenjem ikone), ili nalaženje informacija pomoću pretraživača.
Razlog tome je što su alati UI-ja, poput Siri ili Alexe, počeli svoditi njihove informatičke vještine na jednostavno postavljanje rečenica. Usprkos tome što je informatika predmet koji se predaje od osnovne škole, današnje generacije više ne razumiju osnovne principe softvera i hardvera. Za većinu njih programi su stvari kojima postaviš pitanje kao drugoj osobi, i on ti daje točan odgovor.
Jedan duhoviti aforizam je da nije problem umjetna inteligencija, već ljudska glupost. Istraživanja i anegdotalna iskustva dosljedno pokazuju da sposobnosti kritičkog razmišljanja opadaju iz generacije u generaciju. Nekad su učenici bez razmišljanja prepisivali odgovore iz udžbenika, sada više ne znaju niti naći odgovore u udžbeniku.
Gotovo je sigurno da će se značajan dio stanovništva naviknuti na usluge UI-ja, brkajući ih sa stručnošću informiranih osoba. A nije da velike tvrtke ne ciljaju na to. Nedavno je OpenAI u ChatGPT namjerno dodao sposobnost kompjutorski generiranog glasa kako bi svoj GPT učinio što bliže pravom UI-ju iz nagrađivanog filma "Ona", redatelja Spikea Jonzea iz 2009. ("Her" u izvorniku). Dok ne postignu pravi UI, nastojat će smanjiti razlike između slabog i jakog UI-ja.
Dopuštajući nazivati svaki oblik strojnog učenja UI-jem, a ne prividnom inteligencijom, omogućili smo budućnost u kojoj brojni dio stanovništva neće razumjeti razliku između odgovora dobivenih razmišljanjem i onih dobivenih manje-više sofisticiranim asociranjem riječi.
Američki autor H. L. Mencken zapisao je jednom mizantropski komentar da preko 80% ljudskog roda živi a da nikad ne stvori originalnu misao, odnosno ništa čega se već nisu dosjetile tisuće drugih. Što bi rekao danas na LLM i njihovo široko prihvaćanje? Spremno, kao stručne odgovore, prihvaćamo destilirana pogađanja.
Umjesto u doba UI-ja, ulazimo u doba prividne inteligencije, i one generativnih modela, i one ljudi koji će odrasti na njihovim odgovorima.




























