Automatizirano dobivanje podataka s weba - Automatika narodu
Područje automatiziranog sustavnog pretraživanja weba svakim danom dobiva sve veću važnost, jer količina na webu dostupnih informacija raste te informacije postaju sve vrednije. Više informacija i bolje informacije od iznimne su važnosti za donošenje poslovnih odluka, zbog čega je korisno znati kako (automatizirano) doći do većih količina informacija na Internetu te kako izvući i obraditi tražene informacije
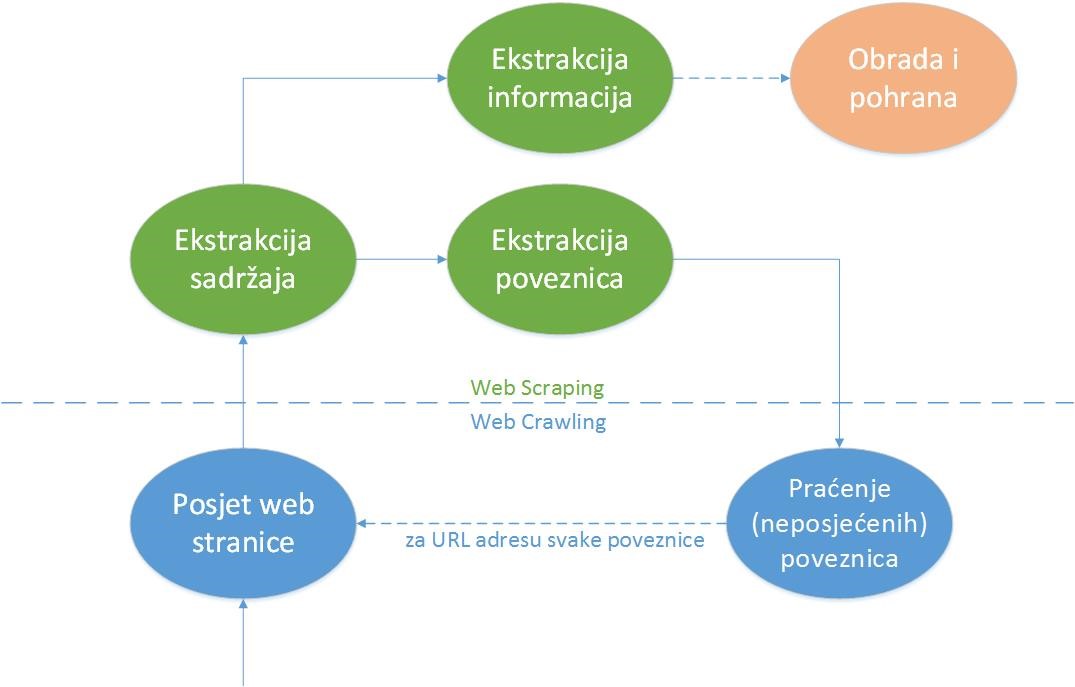
Što je to web-scraping? Dvije glavne definicije u području ekstrakcije web-sadržaja su web-scraping i web-crawling. Web-scraping jest sistematizirana ekstrakcija sadržaja (tekstualnog ili medijskog) s web-stranica, postignuta korištenjem alata zvanih web-scraperi. Koncept web-scrapinga temelji se na korištenju metoda web-crawlinga, automatiziranog sustavnog pretraživanja weba, postignutog praćenjem poveznica web-stranica pomoću web-crawlera.
Procesi web-scrapinga i web-crawlinga čine kontinuirani ciklus: crawlingom dolazimo do HTML dokumenata iza web-stranica, iz kojih izvlačimo željeni sadržaj i poveznice na ostale web-stranice pomoću scrapinga te dalje vršimo crawling po prikupljenim poveznicama.Zašto web-scraping? Poduzećima web-scraping pomaže na mnogo načina. Najčešće je riječ o analizi kompetitivnosti cijena i motrenju konkurencije te istraživanju tržišnih scenarija (trendova) prije plasiranja usluge ili proizvoda na tržište. Osim toga, dodatni agregirani podaci s weba uvijek dobro dođu i u raznim područjima umjetne inteligencije.















