Visoko dostupni SQL Server - Uvijek na usluzi
Kao korisnici raznih usluga, a pri tome ne mislimo samo na usluge iz IT svijeta, već smo se navikli i želimo da su one uvijek dostupne. Osnova mnogih usluga baze su podataka, i njihova visoka dostupnost i mogućnost opravka u slučaju katastrofe preduvjeti su za visoko dostupnu uslugu. Microsoftov SQL Server već odavno ima ugrađen niz mehanizama za postizanje visoke dostupnosti pa pogledajmo neke od njih izbliza…

Kažu da je put u pakao popločan dobrim namjerama, a mi u IT-u bismo mogli kazati kako je popločan nerazumijevanjem, ili još gore, nepoznavanjem tehnologije s kojom radimo. Dok su poslužitelji bili isključivo fizički, stvar je bila relativno jednostavna jer smo za postizanje visoke dostupnosti morali imati više poslužitelja. Elementarna logika nalagala je da nam – ako fizički poslužitelj ne radi, a i dalje želimo pružati uslugu korisnicima – treba drugi poslužitelj na kojemu će ta usluga, servis i/ili baza podataka biti dostupni. Problem nastaje pojavom masovne virtualizacije, pritom uglavnom mislimo na posljednje desetljeće, jer je najčešće virtualizacijska platforma realizirana kao visoko dostupna. Uglavnom se radi o više poslužitelja povezanih u klaster i spojenih na jedan ili više sustava za pohranu, a što čini platformu koja je sposobna odgovoriti na bilo koji problem prouzročen kvarom nekog njenog dijela.
Primjerice, u slučaju kvara fizičkog poslužitelja, na kojemu se izvršavao naš virtualni poslužitelj, platforma je u stanju taj virtualni poslužitelj pokrenuti na drugom fizičkom poslužitelju. Upravo ta sposobnost virtualizacijske platforme stvorila je percepciju da je neki servis visoko dostupan ako se nalazi na visoko dostupnoj fizičkoj platformi – u ovom slučaju virtualizacijskoj platformi. Ovo je samo djelomično točno jer smo prilično otporni na hardverske probleme, ali što je s problemima u samom virtualnom poslužitelju? Njegovo nasilno gašenje i automatsko ponovno pokretanje na drugom virtualizacijskom poslužitelju ne jamči da će se virtualni poslužitelj zaista i pokrenuti. Što u situacijama kada je potrebno održavanje poslužitelja? Dok god se ne pokrene, naša je baza nedostupna, a ne smijemo zaboraviti da vrijeme u kojem će se navedeni procesi završiti ponekad može biti prilično dugo. Zbog svega navedenog za ključne servise kao što su baze podataka potrebno je implementirati neke druge mehanizme koji će nam osigurati njihovu maksimalnu dostupnost.
Na sto načina
Načina na koje naš SQL Server možemo učiniti visoko dostupnim zaista je mnogo, a također ih je moguće i kombinirati te tako proizvesti prilično kompleksna i izdržljiva rješenja. Koji način ćemo koristiti i hoćemo li ga kombinirati s nekim drugim, zavisi od traženog stupnja dostupnosti, ali i o novcu koji nam je na raspolaganju za implementaciju te visoke dostupnosti. Prikazani mehanizmi i tehnologije nisu dostupni samo u SQL Serveru 2016, već u više inačica unatrag, a neke tehnologije tu su gotovo oduvijek.
Database mirroring vjerojatno je najpoznatiji mehanizam osiguravanja visoke dostupnosti SQL Servera, a prvi put je implementiran daleke, 2005. godine. Svoju popularnost može zahvaliti činjenici da je od svoje pojave uvijek prisutan i u standardnim inačicama SQL-a, što ga je učinilo široko dostupnim. Valja napomenuti da je to mehanizam za koji Microsoft navodi unatrag nekoliko inačica da će biti napušten, ali kao što vidimo, to se još nije dogodilo. Trenutačni status je da će biti napušten u nekoj od budućih, ali ne u sljedećoj inačici.
Sustav se sastoji od dva poslužitelja, to jest glavnog ili principala te pričuvnog ili mirrora. Transakcije koje se završe na glavnom, kopiraju se na pričuvni poslužitelj, i tamo se primjenjuju na pričuvnoj kopiji baze koja je nedostupna korisnicima. Database mirroring podržava samo jednu kopiju baze, koje moraju koristiti Full recovery model, i mora se podesiti za svaku bazu posebno ako imamo više baza koje želimo štititi. Može raditi u asinkronom, odnosno High performance, ili sinkronom, odnosno Full safety modu. U asinkronom modu aplikacija koja zapisuje u bazu dobije potvrdu da je transakcija završena čim je zapisana na glavnom poslužitelju, a ista ta transakcija šalje se pričuvnom poslužitelju, što je prije moguće, ali bez jamstva da je tamo zaista i stigla. U tom modu moguć je određeni gubitak podataka ako dođe do kvara glavnog poslužitelja. U sinkronom modu aplikacija koja zapisuje u bazu dobije potvrdu da je transakcija završena kad je ona zapisana na glavnom, prenesena na pričuvni poslužitelj te tamo i zaista zapisana. Kod sinkronog moda treba voditi računa o tome da su poslužitelji blizu jer će značajna latencija mreže utjecati na performanse naše baze – ne zaboravite, aplikacija čeka da se svaka transakcija zapiše na dva mjesta. Sinkroni mod je preduvjet koji nam omogućuje automatsko prebacivanje aktivne baze s principala na mirror u slučaju bilo kakvog problema, ali da bismo mogli koristiti tu funkcionalnost, potreban nam je i treći poslužitelj. On je takozvani svjedok ili witness, koji služi za postizanje kvoruma, to jest preglasavanja. Na njemu je također potrebno instalirati SQL Server, ali, srećom, dovoljna je i inačica Express, koja je besplatna. U slučaju problema, SQL poslužitelj koji vidi i može komunicirati sa svjedokom, proglašava se valjanim i postaje principal za određenu bazu. Kako bi se klijentske aplikacije znale spojiti na pravi poslužitelj u slučaju prebacivanja baze ili failovera, potrebno je u postavkama konekcije definirati imena, kako principala, tako i mirrora.

Log shipping je mehanizam koji je oduvijek prisutan u SQL-u jer se, za razliku od drugih mehanizama koji imaju čarobnjake za konfiguraciju, posebnu logiku i drugo, zasniva na osnovnim mehanizmima SQL-a, kao što su backup i restore. Zahvaljujući toj činjenici, ovaj mehanizam podržava praktično neograničen broj pričuvnih poslužitelja. Sastoji se od periodičke izrade pričuvne kopije transakcijskog loga, njenog kopiranja na jedan ili više pričuvnih poslužitelja i kontinuiranog vraćanja baze iz pričuvnih kopija loga. Podešava se posebno za svaku bazu koju želimo štititi, koja mora koristiti Full recovery ili Bulk logged model, i može raditi samo u asinkronom modu. Nije podržano automatsko prebacivanje s glavnog na neki od dostupnih pričuvnih poslužitelja, već je potrebna ručna intervencija administratora. Jedna od zanimljivih mogućnosti tog načina je vremenski odmak u vraćanju baze iz kopije loga na nekom od pričuvnih poslužitelja, čime bazu možemo dodatno štititi od ljudske pogreške. Pravilnim odabirom vremena čuvanja svih pričuvnih kopija logova i cijelih pričuvnih kopija baze, moguće je vratiti bazu u stanje u kojem je bila u nekom određenom trenutku. Baze na pričuvnim poslužiteljima mogu biti dostupne za čitanje te ih možemo koristiti, primjerice, za izradu raznih izvještaja. Ako implementiramo treći poslužitelj, to jest monitor, na njemu možemo detaljno pratiti status Log shippinga – vrijeme izrade posljednje pričuvne kopije transakcijskog loga, vrijeme posljednjeg kopiranja i bilo koju drugu grešku ili upozorenje. Naravno, osnovni nadzor i informacije možemo vidjeti na glavnom ili pričuvnim poslužiteljima i bez implementacije monitora. Spajanje klijentskih aplikacija obično ide preko DNS aliasa, koji je potrebno ručno ažurirati u slučaju failovera, jer bismo u protivnom morali mijenjati postavke svake aplikacije zasebno. Log shipping često se koristi u kombinaciji s nekim drugim mehanizmom kao način za oporavak u slučaju katastrofe, a drugi primarni mehanizam koristi se za visoku dostupnost.

Always On Failover cluster instance (AO FCI) mehanizam je koji se zasniva na Windows Server Failover Clusteringu (WSFC), i za razliku od do sada predstavljenih mehanizama, štiti cijelu instancu SQL-a, što uključuje sve baze i sva podešavanja. Kako bi to bilo moguće, potrebno je prvo kreirati Windows klaster od raspoloživih poslužitelja, koji se obično nazivaju nodovima i spojeni su na neki dijeljeni sustav za pohranu. Always On FCI instanca je koja je instalirana na svim nodovima klastera, a na mreži je predstavljena jedinstvenim virtualnim imenom i IP adresom. Baze se nalaze na zajedničkom sustavu za pohranu na koji su, kako smo već kazali, spojeni svi nodovi klastera. SQL instanca nalazi se unutar takozvane klaster resursne grupe, čiju sinkroniziranu kopiju postavki održava svaki od nodova, a samo jedan od njih može biti njezin vlasnik u određenom trenutku i naziva se aktivni nod. To znači da SQL instanca, to jest servisi, radi samo na jednom nodu, a na ostalim su nodovima ugašeni. U slučaju problema cijela instanca, odnosno resursna grupa, prebacuje se s jednog noda na drugi, to jest pali se identična instanca na drugom nodu i spaja se na baze koje su na zajedničkom sustavu za pohranu. Cijeli proces nadzire i njime upravlja Windows klaster servis, koji je potpuno nevidljiv klijentskim aplikacijama ili korisnicima, a imamo privid da se radi o SQL instanci koja se izvršava na jednom jedinom poslužitelju, jer je failover uvijek automatski, bez obzira radi li se o planiranom ili neplaniranom failoveru.
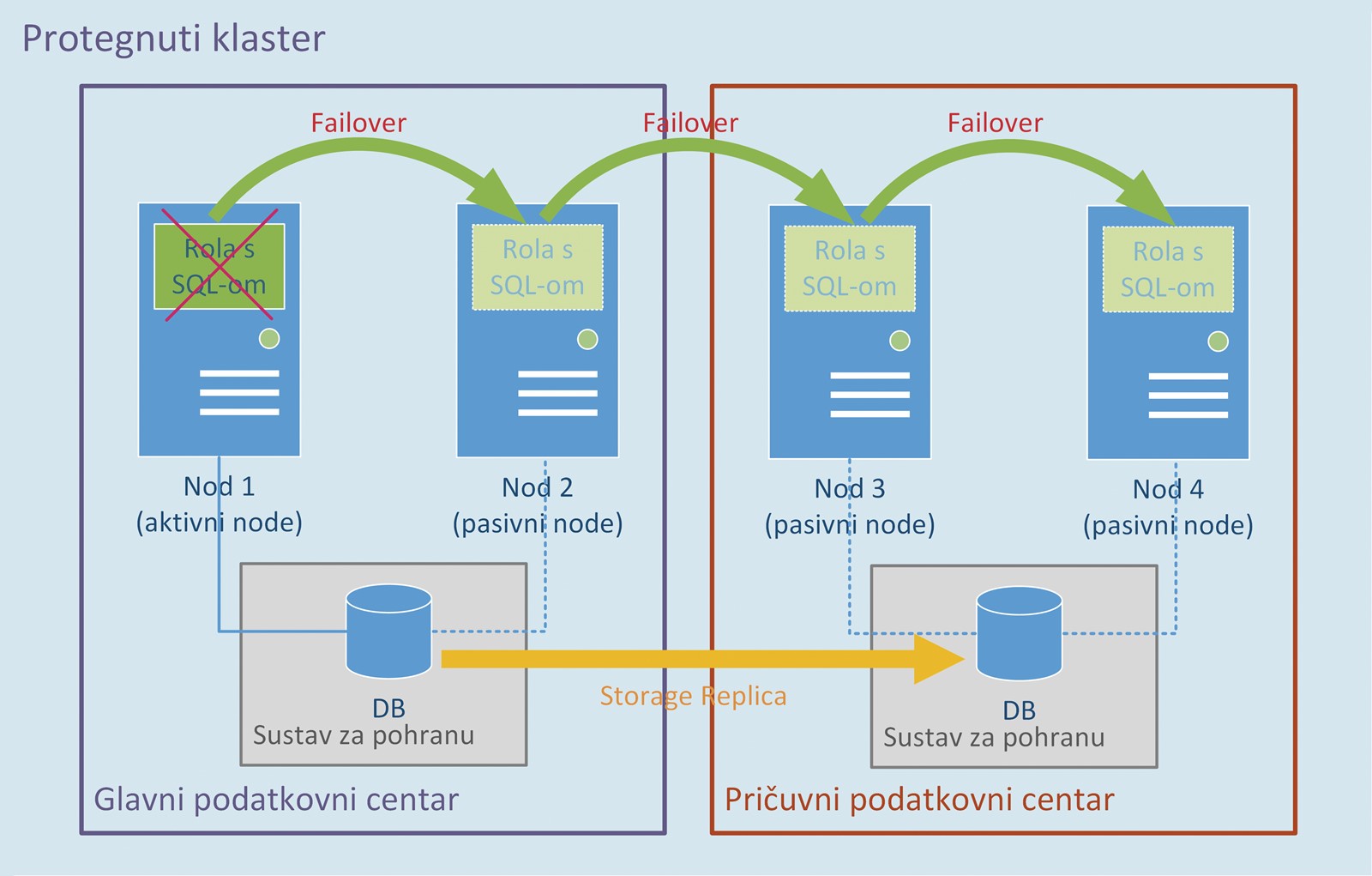
Dostupnost i oporavak
Ovaj mehanizam istovremeno se može koristiti za visoku dostupnost i za opravak u slučaju katastrofe tako da kreiramo protegnuti klaster, kojemu se dio nodova nalazi na udaljenoj lokaciji. Kako bi takav klaster mogao raditi, potrebna su dva sustava za pohranu, po jedan na svakoj lokaciji, koji međusobno repliciraju podatke na blok razini. U slučaju da nam glavna lokacija postane nedostupna, SQL resursna grupa prebacuje se na pričuvnu lokaciju, tamo se spaja na lokalni sustav za pohranu koji sadrži replicirane podatke i nastavlja posluživati klijente. Proces failovera na pričuvnu lokaciju može biti potpuno automatiziran ako to želimo. Gornji scenarij zahtijeva značajna ulaganja u infrastrukturu za pohranu podataka na svakoj od lokacija i dostupan je samo rijetkima. Izlaskom SQL Servera 2016 i Windows Servera 2016 dobili smo tehnologiju nazvanu Storage Replica, koja replicira diskove na blok razini – ispravno kazano volumene, radi s bilo kakvim sustavom za pohranu (lokalni diskovi, FC ili iSCSI, Storage Spaces) – može replicirati podatke sinkrono ili asinkrono, a moguće ju je koristiti i unutar virtualnih poslužitelja. Prilikom sinkrone replikacije svi podaci zapisani na izvorišnom disku sigurno su zapisani i na odredišnom, i ne postoji mogućnost gubitaka podataka. To je vrlo važno za konzistentnost podataka, ali predstavlja pravi izazov za mrežu. SQL Server mora čekati da se podaci zapišu na oba poslužitelja prije nego što dobije potvrdu. Ako koristimo drugu lokaciju za smještaj pričuvnog poslužitelja, mrežna latencija je ključna da bi odziv bio zadovoljavajući i kako bismo uopće mogli uspostaviti sinkronu replikaciju. S druge strane, kod asinkrone replikacije, dok podaci ne stignu na odredišni disk, postoji mogućnost gubitaka podataka. Izgubit ćemo one podatke koji se nisu stigli replicirati zbog male propusnosti veze ili velike latencije, ali u isto vrijeme to nam omogućuje da druga lokacija bude prilično udaljena.
Always On Availability groups mehanizam je koji se također zasniva na Windows Server Failover Clusteringu (WSFC), ali za razliku od SQL Failover Cluster Instance mehanizma, ne štiti cijelu instancu SQL-a, već određenu grupu korisničkih baza. Baze u dostupnoj grupi ili availability group poslužuje jedna od instanci SQL Servera ili availability replica, koje su svaka zasebno instalirane na svakom nodu klastera. Postoje dva tipa replike: primarna, koja sadrži glavnu bazu, i do osam sekundarnih replika koje sadrže pričuvnu kopiju baze. Klaster resursna grupa kreira se za svaku dostupnu grupu, a klaster servis nadzire stanje svake grupe. Važno je napomenuti da tu ne postoji zajednički sustav za pohranu podataka jer je svaka instanca SQL Servera neovisna i koristi lokalne diskove na nodovima. Klaster servis potreban je za nadzor resursnih grupa, međutim SQL Server nije instaliran kao klaster.

Replikacijski mehanizam sličan je mehanizmu Database mirroring, gdje se transakcije prebacuju s primarne replike na sekundarne, i tamo se ažuriraju pričuvne baze. Replikacija može biti sinkrona, to jest u Synchronous-commit modu, ili asinkrona, to jest u Asynchronous-commit modu. U asinkronom modu aplikacija koja zapisuje u bazu dobije potvrdu da je transakcija završena čim je zapisana na primarnoj replici, a ista ta transakcija šalje se sekundarnim replikama što je prije moguće, ali bez jamstva da je zaista tamo i stigla. U tom modu moguć je određeni gubitak podataka ako dođe do kvara noda na kojemu se nalazi primarna replika. U sinkronom modu aplikacija koja zapisuje u bazu dobije potvrdu da je transakcija završena kad je ona zapisana na primarnoj, prenesena na sekundarnu repliku te tamo zaista i zapisana. Automatski failover moguć je samo između replika koje rade u Synchronous-commit modu i koristi se za postizanje visoke dostupnosti na nodovima koji se nalaze na istoj lokaciji. Asynchronous-commit mod koristi se za implementaciju oporavka u slučaju katastrofe, a nodovi koji sadržavaju takve sekundarne replike obično se nalaze na pričuvnoj lokaciji. Mehanizam Always On podržava aktivne sekundarne replike – mogu se čitati – koje možemo koristiti za izradu pričuvnih kopija ili za izradu raznih izvještaja kako bismo smanjili opterećenje na glavnoj bazi. Klijentske aplikacije ili korisnici pristupaju bazama preko takozvanog availability group listenera, koji nije ništa drugo nego virtualno mrežno ime i pridijeljena mu IP adresa. On se nalazi u klasterskoj resursnoj grupi kreiranoj za dostupnu grupu, i u slučaju failovera putuje s njom, pokazujući na SQL Server instancu koja u tom trenutku poslužuje baze. Korisnici i klijentske aplikacije to vide kao jednu SQL instancu koja se izvršava na jednom jedinom poslužitelju. Taj mehanizam može se kombinirati s, primjerice, SQL Failover Cluster Instanceom, tako da je primarna replika smještena na SQL FCI-u, a sekundarna replika na samostalnoj SQL instanci na jednom od nodova. Nod koji sadrži sekundarnu repliku najčešće se nalazi na udaljenoj lokaciji i služi za oporavak u slučaju katastrofe, a visoka dostupnost postiže se korištenjem FCI-ja na glavnoj lokaciji.
Kada smo opisivali Database mirroring kazali smo da Microsoft planira izbaciti taj mehanizam u jednoj od budućih inačica SQL Servera, pri čemu je Always On Availability Groups mehanizam koji bi ga trebao zamijeniti.
Gdje i kako?
Bez obzira koji mehanizam želimo primijeniti, treba naglasiti da je smještaj našeg SQL Servera potpuno nevažan za postizanje visoke dostupnosti. Bez obzira na to imamo li isključivo fizičku infrastrukturu, što je zaista rijetko uz sveprisutnu virtualizaciju, ili su naši poslužitelji isključivo virtualni, implementacija visoke dostupnosti potpuno je jednaka. Kada promatramo virtualne poslužitelje, također nema neke ključne razlike u tome jesu li oni smješteni na našoj fizičkoj infrastrukturi ili se, pak, nalaze u Microsoftovoj oblačnoj platformi, to jest Microsoftovom Azureu. Microsoftov oblak, osim za smještaj naše kompletne infrastrukture, ako ne želimo vlastiti hardver, zanimljiv je kao dodatna lokacija za smještaj naših poslužitelja u slučaju katastrofe. U tom slučaju govorimo o hibridnom rješenju koje uključuje poslužitelje u našoj vlastitoj poslužiteljskoj sobi, ili kako se uvriježilo kazati, u našem podatkovnom centru. To možemo napraviti tako da protegnemo infrastrukturu u oblak, a onda koristimo neki od SQL-ovih mehanizama za oporavak od katastrofe. Možemo, primjerice, kreirati protegnuti klaster i u slučaju da naša glavna lokacija postane nedostupnom, napraviti failover na pričuvni virtualni poslužitelj koji se nalazi u Microsoft Azureu. Rješenje ne mora biti tako kompleksno, već možemo, primjerice, koristiti mehanizam Log shipping kako bismo imali kopiju važne baze na Microsoftovom virtualnom poslužitelju Azure.
Često smo u nedoumici kad nam je na raspolaganju veliki broj mehanizama, i ponekad je teško odlučiti koji je primjeren za rješavanje upravo našeg problema. Nekoliko ključnih čimbenika određuje koji mehanizam primijeniti: zadano vrijeme oporavka, smijemo li izgubiti podatke ili ne, i kolikim sredstvima raspolažemo za implementaciju rješenja, što je gotovo uvijek, ne jezičac, već zaista uteg koji određuje smjer u kojem ćemo krenuti. Što je kraće vrijeme u kojemu moramo uspostaviti dostupnost naše baze, to će i rješenje biti kompleksnije. Zahtjev za sigurnošću podataka i neprihvatljivost njihova gubitka ne mora nužno značiti i skupi sustav. Međutim, ako sustav ne smije dozvoliti gubitak podataka, a u isto vrijeme mora biti iznimno brz, opet ćemo morati realizirati kompleksniji i financijski zahtjevniji sustav.
Microsoft je u svoj SQL Server već odavno ugradio mehanizme kojima nam omogućuje visoku dostupnost i mogućnost za oporavak od katastrofe. Izlaskom Windows Servera 2016, tu prije svega mislimo na tehnologiju Storage Replica, moguće je izgraditi pouzdan i fleksibilan sustav gdje prvi put imamo priliku, čak i kod malih korisnika, implementirati visoku dostupnost i mogućnost oporavka od katastrofe korištenjem komponenti ugrađenih samo u Windows i SQL Server. Pri tome vodite računa da vas implementacija bilo kojeg od navedenih rješenja ne oslobađa izrade pričuvnih kopija. Pričuvne kopije, osim kratkoročne pohrane na diskove, bilo bi dobro pohranjivati i dugoročno na trake. Nehotično obrisanu bazu ili neki njezin dio, opisani visoko dostupni mehanizmi “rado” će replicirati na pričuvne poslužitelje. Zbog svega navedenog nadamo se kako će vas ovaj pregled potaknuti na to da isprobate neke od prikazanih mehanizama i tehnologija te kako ćete neke od njih i primijeniti kako biste osigurali da vaše baze zaista budu visoko dostupne, ali i otporne na moguće katastrofe.
NAPOMENA: Ovaj tekst je izvorno objavljen u časopisu Mreža




















